논문 링크: https://arxiv.org/pdf/1409.1556.pdf
VGG(Visual Geometry Group)Net은 2014년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)에서 준우승을 기록한 모델입니다. VGGNet은 간단한 CNN 기본 아키텍처만을 사용하여 구조가 단순하고 구현이 쉬워, 다양한 분야에서 기본 모델로 널리 사용되고 있습니다. 대표적인 버전으로는 convolution layer가 13개인 VGG16과 16개인 VGG19가 있습니다.

Architecture
VGG16의 구조는 다음과 같습니다:
- Input Image Size: 224x224x3 (R, G, B)
- Convolution Layers: 모든 convolution layer에는 3x3 크기의 필터가 사용됩니다. 이는 상, 하, 좌, 우, 중심을 고려할 수 있는 최소한의 크기입니다.
- 1x1 Convolution: 비선형성을 추가하기 위해 적용됩니다.
- Pooling Layers: Max-pooling을 사용하며, 2x2 크기와 stride 2로 구성됩니다.
- Fully-Connected Layers: 3개의 fully-connected layer가 있으며, 마지막 layer는 1000-way softmax로 구성되어 있습니다.

각 Layer 세부 설명
(1층) Convolution Layer1-1: 224x224x3 크기의 input image에 convolution operation를 진행한 이후에도 크기를 보존하기 위해 P = (K - 1) / 2 공식에 따라 zero padding을 1만큼 진행하여 226x226x3 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x3 크기의 필터 64개로 stride가 1인 convolution operation을 진행하여
224x224x64 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x64 크기의 필터 64개로 convolution operation을 진행하여 224x224x64 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(①)
(2층) Convolution Layer1-2: 224x224x64 크기의 input image에 zero padding을 1만큼 진행하여 226x226x64 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x64 크기의 필터 64개로 stride가 1인 convolution operation을 진행하여 224x224x64 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x64 크기의 필터 64개로 convolution operation을 진행하여 224x224x64 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(②)
Pooling Layer1: 224x224x64 크기의 input image에 2x2 크기의 pooling window로 stride가 2인 Max-pooling을 진행하여 112x112x64 크기의 feature map을 생성합니다.(③)
(3층) Convolution Layer2-1: 112x112x64 크기의 input image에 zero padding을 1만큼 진행하여 114x114x64 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x64 크기의 필터 128개로 stride가 1인 convolution operation을 진행하여 112x112x128 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x128 크기의 필터 128개로 convolution operation을 진행하여 112x112x128 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(④)
(4층) Convolution Layer2-2: 112x112x128 크기의 input image에 zero padding을 1만큼 진행하여 114x114x128 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x128 크기의 필터 128개로 stride가 1인 convolution operation을 진행하여 112x112x128 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x128 크기의 필터 128개로 convolution operation을 진행하여 112x112x128 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(⑤)
Pooling Layer2: 112x112x128 크기의 input image에 2x2 크기의 pooling window로 stride가 2인 Max-pooling을 진행하여 56x56x128 크기의 feature map을 생성합니다.(⑥)
(5층) Convolution Layer3-1: 56x56x128 크기의 input image에 zero padding을 1만큼 진행하여 58x58x128 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x128 크기의 필터 256개로 stride가 1인 convolution operation을 진행하여 56x56x256 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x256 크기의 필터 256개로 convolution operation을 진행하여 56x56x256 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(⑦)
(6층) Convolution Layer3-2: 56x56x256 크기의 input image에 zero padding을 1만큼 진행하여 58x58x256 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x256 크기의 필터 256개로 stride가 1인 convolution operation을 진행하여 56x56x256 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x256 크기의 필터 256개로 convolution operation을 진행하여 56x56x256 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(⑧)
(7층) Convolution Layer3-3: 56x56x256 크기의 input image에 zero padding을 1만큼 진행하여 58x58x256 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x256 크기의 필터 256개로 stride가 1인 convolution operation을 진행하여 56x56x256 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x256 크기의 필터 256개로 convolution operation을 진행하여 56x56x256 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(⑨)
Pooling Layer3: 56x56x256 크기의 input image에 2x2 크기의 pooling window로 stride가 2인 Max-pooling을 진행하여 28x28x256 크기의 feature map을 생성합니다.(⑩)
(8층) Convolution Layer4-1: 28x28x256 크기의 input image에 zero padding을 1만큼 진행하여 30x30x256 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x256 크기의 필터 512개로 stride가 1인 convolution operation을 진행하여 28x28x512 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x512 크기의 필터 512개로 convolution operation을 진행하여 28x28x512 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(⑪)
(9층) Convolution Layer4-2: 28x28x512 크기의 input image에 zero padding을 1만큼 진행하여 30x30x512 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x512 크기의 필터 512개로 stride가 1인 convolution operation을 진행하여 28x28x512 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x512 크기의 필터 512개로 convolution operation을 진행하여 28x28x512 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(⑫)
(10층) Convolution Layer4-3: 28x28x512 크기의 input image에 zero padding을 1만큼 진행하여 30x30x512 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x512 크기의 필터 512개로 stride가 1인 convolution operation을 진행하여 28x28x512 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x512 크기의 필터 512개로 convolution operation을 진행하여 28x28x512 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(⑬)
Pooling Layer4: 28x28x512 크기의 input image에 2x2 크기의 pooling window로 stride가 2인 Max-pooling을 진행하여 14x14x512 크기의 feature map을 생성합니다.(⑭)
(11층) Convolution Layer5-1: 14x14x512 크기의 input image에 zero padding을 1만큼 진행하여 16x16x512 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x512 크기의 필터 512개로 stride가 1인 convolution operation을 진행하여 14x14x512 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x512 크기의 필터 512개로 convolution operation을 진행하여 14x14x512 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(⑮)
(12층) Convolution Layer5-2: 14x14x512 크기의 input image에 zero padding을 1만큼 진행하여 16x16x512 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x512 크기의 필터 512개로 stride가 1인 convolution operation을 진행하여 14x14x512 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x512 크기의 필터 512개로 convolution operation을 진행하여 14x14x512 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(⑯)
(13층) Convolution Layer5-3: 14x14x512 크기의 input image에 zero padding을 1만큼 진행하여 16x16x512 크기의 padding image를 얻습니다.
그다음 이 padding image에 3x3x512 크기의 필터 512개로 stride가 1인 convolution operation을 진행하여 14x14x512 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형 활성화를 수행합니다.
이후 1x1x512 크기의 필터 512개로 convolution operation을 진행하여 14x14x512 크기의 feature map을 생성하고 ReLU 함수를 적용하여 비선형성을 더 부여합니다.(⑰)
Pooling Layer5: 14x14x512 크기의 input image에 2x2 크기의 pooling window로 stride가 2인 Max-pooling을 진행하여 7x7x512 크기의 feature map을 생성합니다.(⑱)
Flatten Layer: flatten layer는 다차원 배열을 1차원 벡터로 변환하는 작업을 수행하는 layer입니다.
7x7x512 크기의 feature map을 7x7x512 = 25,088개의 요소를 가진 1차원 벡터를 출력합니다.(⑲)
(14층) Fully-connected Layer1: 1x1x4096. 즉, 4096개의 뉴런을 가집니다.
이전 단계의 출력인 1x1x25,088의 1차원 벡터와 fully-connect됩니다.
또한 학습 단계에서 0.5의 비율로 dropout됩니다.(⑳)
(15층) Fully-connected Layer2: 1x1x4096. 즉, 4096개의 뉴런을 가집니다.
fully-connected layer1의 4096개의 뉴런과 fully-connect됩니다.
또한 학습 단계에서 0.5의 비율로 dropout됩니다.(㉑)
(16층) Fully-connected Layer3: ILSVRC의 과제는 주어진 이미지를 1000개의 클래스로 분류하는 것입니다.
소프트맥스 함수에 1000개의 뉴런을 매핑시키기 위해 1x1x1000. 즉, 1000개의 뉴런을 가집니다.
fully-connected layer2의 4096개의 뉴런과 fully-connect됩니다.(㉒)
Softmax Function: fully-connected layer2의 1x1x1000의 출력을 클래스에 대한 확률로 변환하여 최종적으로 가장 높은 확률을 가지는 클래스를 예측하게 됩니다.(㉓)
Configurations

위 표는 본 논문에서 평가된 convolution network들의 구성입니다. A network에는 11개의 layer(8개의 convolution layer, 3개의 fully-connected layer)로 시작하여 E network에는 19개의 layer(16개의 convolution layer, 3개의 fully-connected layer)가 존재합니다.
convolution layer의 채널 수는 64부터 각 pooling layer 이후 두 배씩 증가하여 512까지 도달합니다.
또한 이전에 AlexNet 논문 리뷰에서 설명했던 LRN(Local Response Normalization)는 학습 성능을 향상시키지 않고
메모리 소비와 계산 시간을 증가시키기 때문에 A-LRN 네트워크 이외에는 적용하지 않았습니다.
A-LRN 네트워크의 파라미터는 AlexNet과 동일합니다.

위 표는 본 논문의 각 convolution network들의 파라미터 수입니다.
본 네트워크는 convolution layer의 폭과 필터의 크기가 더 큰 Sermanet et al., 2014의 네트워크(파라미터 수:144M)보다 깊이가 깊음에도 불구하고, 파라미터 수가 더 작거나 같습니다.
Filter Size
Krizhevsky et al., 2012는 첫 번째 convolution layer에서 크기가 11x11인 필터를 사용했고,
Zeiler & Fergus, 2013; Sermanet et al., 2014는 크기가 7x7인 필터를 사용했습니다.
반면 본 모델은 전반적으로 크기가 3x3인 필터를 사용합니다.
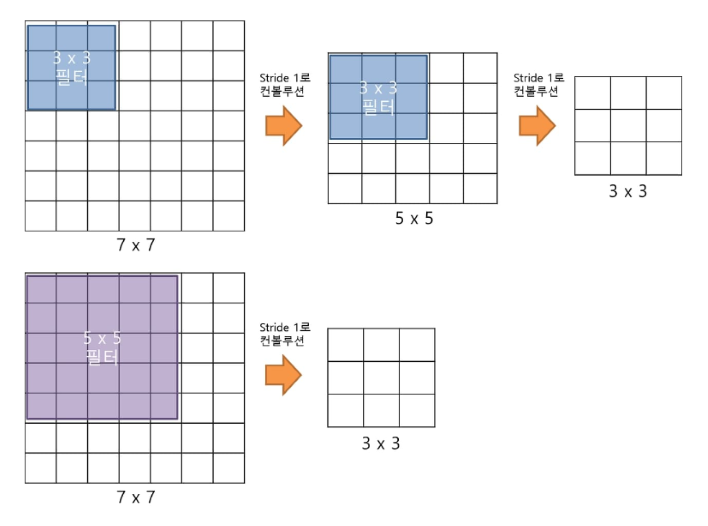
위 그림과 같이, 필터의 크기가 3x3인 convolution operation을 두 번 진행하면 필터의 크기가 5x5인 convolution operation을 한 번 진행한 것과 같은 크기의 feature map을 얻습니다.
또한 필터의 크기가 3x3인 convolution operation을 세 번 진행하면 필터의 크기가 7x7인 convolution operation을 한 번 진행한 것과 같은 크기의 feature map을 얻습니다.
이렇게 작은 필터로 여러 번 convolution operation을 진행했을 때 얻는 이점은
1. 비선형 활성화 함수를 더 여러번 통과시켜 비선형성을 더 부여합니다.
여기서 비선형성을 부여한다는 것은 복잡한 패턴과 관계를 표현할 수 있는 능력을 갖추게 하는 것을 의미합니다.
1x1 convolution layer를 계속해서 통과시킨 이유도 이것입니다.
2. 파라미터 수를 감소시킵니다.
채널이 C개고 필터의 크기가 7x7인 단일 convolution layer라면, 총 49C^2개의 파라미터를 필요로 합니다.
반면, 채널이 C개고 필터의 크기가 3x3인 convolution layer 3개를 사용한다면, 총 27C^2개의 파라미터를 필요로 합니다.
CLASSIFICATION FRAMEWORK
이번 섹션에서는 본 모델의 학습 및 평가의 세부 사항을 설명하겠습니다.
Training
- Optimizer: momentum이 0.9, weight decay가 0.0005인 mini-batch stochastic gradient descent (SGD)를 사용합니다.
- Batch Size: 256
- Dropout: 처음 두 fully-connected layer에서 0.5의 비율로 적용됩니다.
- Learning Rate: 초기값은 0.01이며, 학습 중 검증 세트의 정확도가 늘어나지 않을 때마다 1/10로 감소시킵니다.
Image Pre-processing
본 모델의 입력 이미지 전처리 방법에는 (1) ARCHITECTURE 설명한 방법 이외에도 2개가 더 있습니다.
1. 채널 순서 변경: 일반적으로 많이 사용되는 RGB 순서와는 다르게, VGGNet은 입력 이미지의 채널 순서를 BGR로 사용합니다.
2. 크기 조정: 입력 이미지의 크기를 모델이 요구하는 크기로 조정합니다. 크기 조정또한 두 가지 방법으로 나뉩니다. S는 학습 스케일로, 학습 이미지를 resize하고 crop할 때 사용되는 작은 쪽의 길이입니다.
2-1 단일 스케일 학습: S=256과 S=384 두 가지 고정 스케일로 모델을 학습시켰고, 각각의 모델을 평가했습니다.
먼저 S=256으로 네트워크를 학습시킨 다음, S=384 네트워크를 빠르게 학습시키기 위해 S=256으로 사전 학습된 가중치를 초기화했습니다.
2-2 다중 스케일 학습: S를 [Smin, Smax] 범위에서 무작위로 샘플링하여 각 학습 이미지의 크기를 조정합니다. Smin은 256이고 Smax는 512로 사용되었습니다.
Testing
테스트 시에는 테스트 이미지의 가장 작은 측면을 나타내는 미리 정의된 값인 Q를 사용합니다. 테스트 이미지를 가로와 세로 크기로 조정할 때 Q를 사용하여 다양한 비율로 이미지를 조정합니다. 이후, 첫 번째 fully-connected layer는 7x7 convolution layer로, 두 번째와 세 번째 fully-connected layer는 1x1 convolution layer로 변환됩니다. 변환된 모델은 Q로 조정된 테스트 이미지에 적용되어 클래스 수(1000개)만큼의 채널 수를 가진 class score map을 생성합니다.
이 score map은 입력 이미지의 크기에 따라 가변적인 공간 해상도를 가지게 되며, 이를 고정된 크기의 벡터로 변환하기 위해 공간 평균화 또는 합계 풀링을 사용합니다. 이는 각 클래스별로 하나의 값으로 압축하는 것을 의미합니다. 또한, 테스트 세트를 보강하기 위해 이미지를 수평으로 뒤집고, 원래 이미지와 뒤집힌 이미지의 Softmax class posterior(각 클래스에 대한 확률 값)를 평균화하여 이미지의 최종 점수를 얻습니다.
Results
- Single Scale Evaluation: 단일 스케일 평가에서 VGGNet은 모델의 깊이에 따라 성능이 향상됨을 보여줍니다. 특히, 3x3 convolution layer를 여러 번 사용하는 것이 성능 향상에 크게 기여합니다.
- Multi-Scale Evaluation: 다중 스케일 평가에서도 VGGNet은 더 깊은 모델이 더 나은 성능을 보입니다.
- Multi-Crop Evaluation: multi-crop 평가가 dense convolution network 평가보다 더 나은 성능을 보이며, 두 방식의 softmax 출력값의 평균이 가장 좋은 성능을 보입니다.
- ConvNet Fusion: 여러 모델의 softmax class 후보군을 평균화하여 출력을 결합한 결과, 성능이 향상됩니다. 7개의 모델을 Ensemble한 경우 top-5 error가 7.3%로 감소했습니다.

- Multi-Scale Evaluation: 다중 스케일 평가에서도 VGGNet은 더 깊은 모델이 더 나은 성능을 보입니다.

- Multi-Crop Evaluation: multi-crop 평가가 dense convolution network 평가보다 더 나은 성능을 보이며, 두 방식의 softmax 출력값의 평균이 가장 좋은 성능을 보입니다.

- ConvNet Fusion: 여러 모델의 softmax class 후보군을 평균화하여 출력을 결합한 결과, 성능이 향상됩니다. 7개의 모델을 Ensemble한 경우 top-5 error가 7.3%로 감소했습니다.

Comparison with the State of the Art
VGGNet은 이전 세대의 모델들을 크게 능가하며, 단일 모델로는 GoogLeNet보다 0.9% 낮은 top-5 error를 기록했습니다. Ensemble을 통해 top-5 error를 6.8%까지 감소시켰습니다.

Conclusion
VGGNet 논문을 통해 간단하고 기본적인 CNN 아키텍처만으로도 주목할 만한 성능을 낼 수 있음을 확인할 수 있었습니다. 또한, 여러 모델을 Ensemble하는 것보다 상호 보완성이 좋은 모델을 선택하여 Ensemble하는 것이 성능 향상에 더 효과적이라는 것을 알게 되었습니다. VGGNet은 구조의 단순성과 뛰어난 성능 덕분에 다양한 딥러닝 응용 프로그램의 기본 모델로 자리잡았습니다. 논문을 읽기 전에는 대회에서 2등을 한 VGGNet이 어떻게 1등을 한 GoogLeNet보다 더 널리 사용되는지 이해가 잘 되지 않았는데 COMPARISON WITH THE STATE OF THE ART의 표를 보며 단일 모델로는 VGGNet이 더 낮은 오차율을 보이고 Ensemble을 한 모델의 경우에도 오차율의 차이가 매우 작은 것을 보며 납득했습니다. 물론 간단한 architecture도 한몫했을 것이라고 생각합니다.



