[논문 리뷰] Denoising Diffusion Probabilistic Models(Diffusion Model)
Diffusion model
Diffusion 모델은 variational inference을 통해 유한한 시간 내에 데이터와 일치하는 샘플을 생성하도록 학습됩니다.
이 모델은 샘플링의 반대 방향으로 데이터에 노이즈를 점진적으로 추가하는 과정을 거쳐 작동합니다.

저자가 말하는 논문의 주요 기여는 아래와 같습니다.
1. Diffusion 모델이 고품질 샘플을 생성할 수 있음을 입증합니다.
2. 특정 매개변수가 여러 노이즈 수준에서의 score matching 및 Langevin dymamics와 등가성을 가진다는 것을 발견하였습니다.
3. 샘플링 절차가 autoregressive decoding을 일반화한 점진적 디코딩의 일종임을 제시합니다.
Diffusion 모델은 데이터의 확률 분포를 학습하는 latent variable model의 한 종류로, 데이터 x0와 동일한 차원을 가진 latent variable x1, …, xt를 사용합니다. 모델의 목표는 이러한 latent variable을 통해 고품질의 새로운 샘플을 생성하는 것입니다.
Diffusion 모델의 학습 과정을 이해하기 위해 아래 두 가지 과정에 대한 이해가 필요합니다.
1. Forward Process
Forward Process는 데이터에 점진적으로 노이즈를 추가하여 latent variable을 만드는 과정입니다. 이 과정은 아래 규칙에 따라 이루어집니다.
· 데이터 x0에 점진적으로 가우시안 노이즈를 추가하여 x1, x2, …, xT라는 latent variable을 만듭니다.
· 각 단계에서 노이즈를 추가하는 방법은 아래와 같습니다:

여기서 βt는 variance schedule로, 각 단계에서 추가되는 노이즈의 크기를 나타냅니다.
1.1 Forward Process Variance βt
βt는 Reparameterization을 통해 학습하거나 하이퍼파라미터로 설정할 수 있습니다. 주목할 점은 일일히 단계를 거쳐 샘플링하는 것이 아니라, 임의의 시간 t의 상태로 한번에 샘플링이 가능하다는 것입니다. 이를 위해 아래와 같은 표기법을 사용할 수 있습니다.

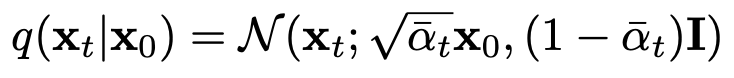
1.2 Forward Process & Lt
Lt는 특정 시간 t에서의 loss function 값으로(아래 Learning Process 참고), 앞서 설명한 듯이 βt는 Reparameterization을 통해 학습이 가능하지만, 이를 상수로 고정하면 학습 중 Lt를 상수 취급할 수 있어 모델의 학습이 단순해집니다.
2. Reverse Process
Reverse Process는 Forward Process에서 추가된 노이즈를 제거하여 원래의 데이터로 복원하는 과정입니다.
· Reverse Process는 학습된 Markov Chain으로 정의됩니다.
· Markov Chain은 아래와 같은 방식으로 각 단계에서 노이즈를 제거하는 방법을 학습합니다:

여기서 Σθ와 μθ는 각각 분산과 평균입니다.
2.1 Reverse Process & L1:T-1
Reverse Process에서 사용되는 주요 요소는 아래와 같습니다.
· Reverse Process Distiibution: 아래와 같은 분포를 알아내기 위해, 먼저 Σθ, μθ를 알아내야 합니다.

· Variance Σθ(xt, t): 분산 Σθ을 고정된 값 σ_t^2I로 정의합니다. 실험적으로 아래 두 가지 값을 사용했고, 이 두 값은 비슷한 결과를 냈습니다.

· Mean μθ(xt, t): 평균 μθ의 정의를 위해 분포를 아래와 같이 재정의합니다.

따라서, loss function이 아래와 같이 정의됩니다.

모델이 μ~θ를 직접 예측하는 대신, ϵ를 예측하여 간접적으로 계산하기 위해, 아래와 같은 Posterior 공식에,

아래와 같이 Reparameterization 합니다.
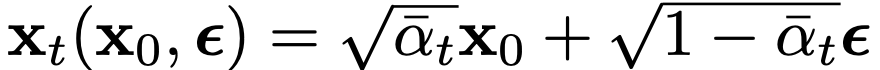
또한, 아래의 공식을 함께 위의 Lt-1 식에 적용하면(Learning Process에 설명되어 있습니다),

아래와 같은 식을 유도할 수 있습니다.

여기서 ϵθ(xt, t)는 주어진 xt에서 ϵ를 예측하는 함수입니다. 따라서, 모델은 xt에서 ϵ를 예측하고 이를 통해 μ~θ의 간접적인 계산이 가능합니다. 성능 비교는 아래 Experiments에서 확인할 수 있습니다.
Learning Process
모델은 variational inference를 통해, 데이터와 일치하는 샘플을 생성할 수 있도록 학습됩니다.
· 학습의 목표는 variational bound를 최적화하는 것입니다.

· 효율적인 학습을 위해 Stochastic Gradient Descent(SGD)를 사용하여 loss function L을 최적화합니다. 또한 L을 아래와 같이 재작성함으로써 variance를 감소시켜 효율적인 학습이 가능하게 합니다.

위 식에서, KL divergence를 통해 분포 pθ와 q를 비교합니다. 또한 분포 q가 x0를 기준으로 조건화되었을 때, 계산이나 분석이 용이해집니다.

위 식에서, 아래와 같은 식을 유도할 수 있습니다.

Data scaling
이 논문에서는 이미지 데이터의 픽셀값이 0~255의 정수로 구성되어 있고, 이미지 데이터가 아래와 같이 [-1, 1] 범위로 스케일링된다고 가정하고 있습니다.

한가지 주목할 점은 x1에서 x0로 변하는 Reverse Process의 마지막 항인 pθ(x0 | x1)을 독립적인 Discrete Decoder로 설정하는 것입니다. 이는 variational bound를 통해 데이터의 lossless codelength를 최적화하기 위함입니다. 이 Discrete Decoder는 아래의 정규 분포에서 유도됩니다:


여기서 δ+(x)와 δ-(x)는 아래와 같이 정의됩니다.

Variational Bound Redefine
위에서 설명한 Reverse Process와 Discrete Decoder를 통해 variational bound가 모델의 파라미터인 θ에 대해 미분 가능하게 되어 학습이 가능해졌습니다. 그러나 샘플 품질 향상 및 구현 단순화를 위해 아래와 같이 간소화된 variational bound가 도입됩니다.

위 식에서 특정 시간 t는 1~T 까지 균일하게 분포되어 있습니다.
· t=1인 경우: 이전에 설명한 discrete decoder의 적분식을 확률 밀도 함수로 근사하여 Lo를 계산합니다. 이때, 노이즈의 분산과 edge effect를 무시합니다.
· 1 < t < T인 경우: 위 식을 사용합니다.
· t=T인 경우: βt가 상수로 고정되기 때문에 LT가 나타나지 않습니다.
Experiments
실험의 설정은 아래와 같습니다.
· Max Time Step: T=1000
· Forward Process Variance: β1= 10^-4에서 βT=0.02로 선형적으로 증가하도록 설정
· Backbone: 마스킹을 사용하지 않은 PixelCNN++와 유사한 U-Net 구조
· Normalization: group normalization
· Dataset: CIFAR-10, CelebA-HQ, LSUN
· Evaluation Metrics: Inception score, FID score, negative log likelihood
CIFAR-10

위 표는 CIFAR-10에 대한 Inception score(IS), FID score, negative log likelihood(NLL)를 보여줍니다.
FID: 제안하는 모델의 FID score는 3.17로 Unconditional한 모델 중 가장 좋은 샘플 품질을 보였으며, Conditional Model들과 비교해도 좋은 성능을 보입니다.
Negative Log Likelihood: 위 표는 또한 제안하는 모델의 lossless codelength. 즉, nagetive log likelihood를 보여줍니다. training set과 test set의 차이는 0.03 bits/dim으로, overfitting 되지 않았음을 나타내며 다른 likelihood 기반 모델과 비슷하지만, 다른 likelihood 기반 모델과 비교하여 낮은 성능을 보입니다.
Reverse Process Setting & Training Object Ablation

위 표는 CIFAR-10 데이터셋에서 reverse process에서 파라미터의 설정과 학습 목표가 샘플 품질에 미치는 영향을 보여줍니다. 표를 살펴보면, variational bound를 사용한 것보다 단순화된 목표를 사용하여 학습했을 때 샘플 품질이 더 좋아짐을 확인할 수 있습니다. 또한, reverse process에서 variance를 고정하는 것이 학습에 포함시키는 것보다 안정적이고 높은 샘플 품질을 갖는 것을 확인할 수 있습니다. 또한, variational bound를 통한 학습 시에는 ϵ를 통한 간접 예측과 μ~의 직접 예측이 비슷한 성능을 보이지만, 단순화된 목표를 사용한 학습에서는 ϵ를 통한 간접 예측이 더 좋은 성능을 보입니다.
Conclusion
이 논문에서는 Diffusion 모델이 고품질 샘플을 생성할 수 있음을 입증했습니다. 특히, 특정 매개변수가 여러 노이즈 수준에서 score matching 및 Langevin dynamics와 등가성을 가진다는 것을 발견하고, 점진적 디코딩을 통해 더 정교한 샘플을 생성할 수 있음을 보여주었습니다. 또한, variational bound를 간소화하여 학습 과정을 단순화하고 샘플 품질을 향상시킬 수 있음을 보였습니다. 특히, 기존의 생성 모델인 GAN과 VAE과 비교할 때, GAN은 좋은 샘플링 성능을 보이지만 훈련이 불안정할 수 있고, VAE는 안정적인 훈련을 제공하지만 샘플 품질이 떨어질 수 있습니다. 반면, Diffusion 모델은 안정적인 학습 과정과 고품질 샘플을 모두 제공할 수 있습니다. 개인적으로, Diffusion 모델의 잠재력이 인상적이었습니다. 이후 논문들을 아직 읽지 못했지만, 이미지 생성 분야에 큰 파장을 몰고올 것이라 예상합니다.