기존의 Simple GAN은 구조와 학습이 불안정하고, 결과가 어떻게 도출되는지에 대한 명확한 설명이 부족했습니다. 이러한 문제를 해결하기 위해 제안된 것이 바로 Deep Convolutional GANs (DCGANs)입니다.
논문의 주요 특징
- 안정적인 학습: 대부분의 상황에서 안정적인 학습이 가능한 Deep Convolutional GANs을 제안하였습니다.
- 우수한 성능: DCGAN의 판별자가 다른 비지도 이미지 분류 알고리즘과 대등한 성능을 보였습니다.
- 필터 시각화: 학습이 완료된 필터를 시각화하여, 어떤 필터에서 어떤 객체가 생성되는지를 보여줍니다.
- 벡터 산술 연산: DCGAN 이미지에서 벡터의 산술 연산이 가능합니다.
Technical details
Spatial Pooling -> Strided Convolution: 기존의 Spatial Pooling을 Strided Convolution으로 대체하여, 생성자와 판별자가 스스로 Spatial Down Sampling을 학습하도록 했습니다.

Fully-connected Layer 제거: 노이즈 벡터 z를 입력하는 Input layer와 Softmax layer를 제외하고 Fully-connected layer를 제거했습니다.
Batch Normalization: 각 유닛의 입력을 정규화하여 학습을 안정화했습니다. 하지만 모든 layer에 Batch Normalization을 적용하면 문제가 발생했기 때문에, 생성자의 출력과 판별자의 입력에는 적용하지 않았습니다.
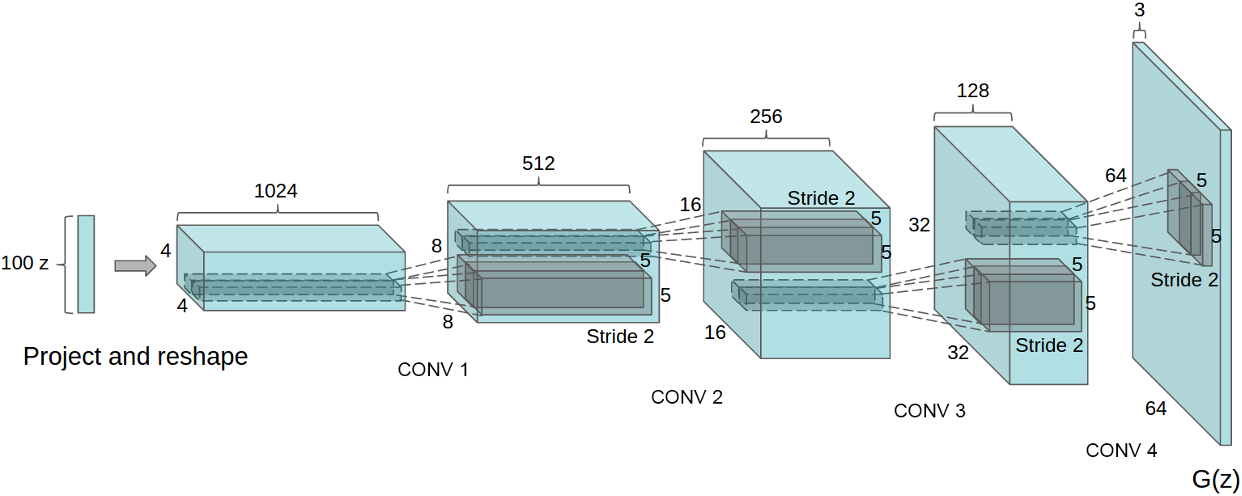
Architecture
생성자의 Output layer에는 tanh 함수를, 다른 모든 layer에는 ReLU 함수를 배치했습니다. 판별자의 모든 layer에는 Leaky ReLU 함수를 사용했습니다.
Experiments
CIFAR-10: CIFAR-10 데이터셋에서 판별자의 분류 성능이 k-means 알고리즘보다 뛰어남을 보였습니다. 또한, DCGAN은 CIFAR-10으로 사전 학습되지 않아도 도메인에 크게 의존하지 않음을 확인했습니다.

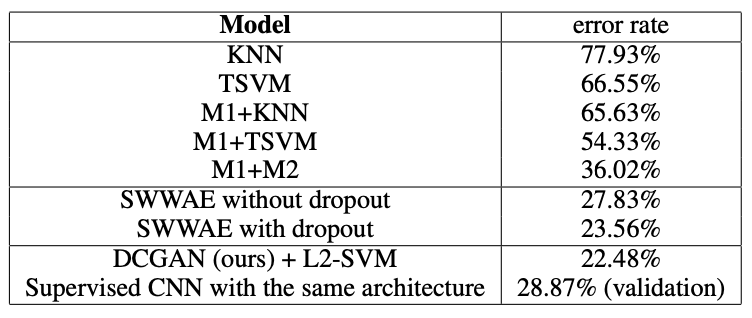
SVHN: 레이블이 제한적인 상황에서 SVHN 데이터셋을 이용해, DCGAN의 판별자를 특성 추출기로 활용하여 L2-SVM 분류기를 훈련시키는 방법을 제안했습니다. 이는 CNN이 결정적인 요소가 아님을 입증하기 위해, 동일한 구조에 CNN 모델을 활용하여 평가했습니다.
Additional Experiments
Walking the Latent Space: 각 줄의 z(latent vector)의 값을 조금씩 바꾸면 결과가 부드럽게 변경되는 것을 확인할 수 있었습니다.



결론
이 논문은 적대적 학습 프레임워크를 통해 높은 품질의 이미지를 생성할 수 있는 새로운 방법을 제시하며, 이미지 생성 분야에서 그 가능성을 입증했습니다. DCGAN의 핵심은 생성자와 판별자의 동적 경쟁을 통해 서로의 성능을 향상시키는 것으로, 이는 기존의 생성 모델이 가지고 있던 한계를 극복할 수 있게 했습니다. 개인적으로, DCGAN의 가장 인상 깊었던 점은 단순히 이미지를 생성하는 것을 넘어, 생성된 이미지에서 벡터 연산이 가능하다는 점이었습니다. 이는 이미지 생성 모델의 새로운 가능성을 열어주는 부분이라고 생각합니다. 또한, 필터 시각화를 통해 모델이 어떻게 학습하는지 이해할 수 있다는 점도 매우 흥미로웠습니다.



