Image-to-Image Translation이란?
Image-to-Image Translation은 입력 이미지를 다른 양상의 출력 이미지로 변환하는 것을 말합니다. 예를 들어, 흑백 사진을 컬러 사진으로 변환하거나, 낮 시간의 사진을 밤 시간의 사진으로 변환하는 작업이 포함됩니다. 이 과정은 결국 픽셀 단위에서 예측을 수행하는 문제입니다.

Objective Function
Pix2pix의 Objective function은 Conditional GAN(cGAN)을 기반으로 합니다. 추가적으로 생성자가 판별자를 잘 속이고 실제 이미지와 더 비슷한 이미지를 생성하도록 L1 손실 함수를 사용합니다. Pix2pix는 생성자가 노이즈 를 무시하는 방향으로 학습되므로 노이즈 를 사용하지 않습니다.
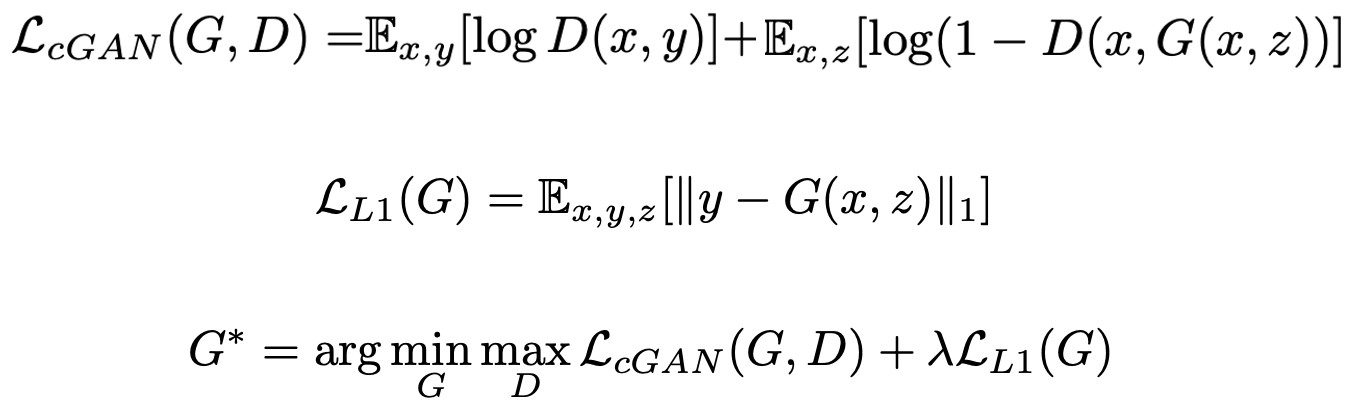
Generator
U-Net
Image-to-Image Translatio이 갖는 문제로 입력의 일부 정보가 그대로 출력에 사용되는 것이 있습니다. 이를 해결하기 위해 인코더-디코더 네트워크에 스킵 커넥션(skip connection)이 추가된 U-Net 구조를 생성자로 활용합니다.

U-Net 구조를 사용하는 것이 더 좋은 성능을 보이는 것을 확인할 수 있습니다.

Discriminator
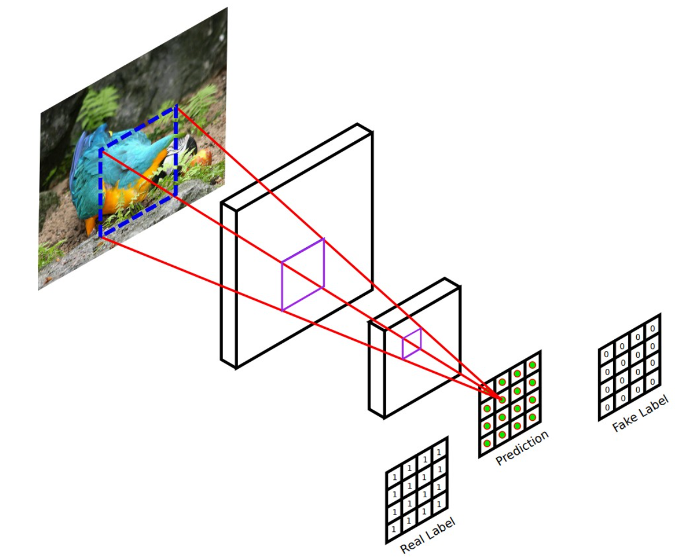
PatchGANs
PatchGANs은 L1 손실을 사용할 때 픽셀의 변화 정도가 낮은 성분을 잘 검출합니다. PatchGANs은 로컬 이미지 패치에 대해 진위 여부를 판단하여 픽셀 변화 정도가 높은 성분을 검출합니다. 또한 적은 파라미터 수를 가지고 학습 속도가 빠른 장점이 있습니다. PatchGANs를 판별자로 활용합니다.
Experiment
실험에서 cGAN의 조건 로 세그멘테이션 맵이나 이미지가 주어집니다.

이미지에 빈 부분이 있을 경우, 생성자는 이미지의 빈 부분을 예측하여 새로운 픽셀값을 생성하고, 판별자는 생성된 이미지의 빈 부분이 자연스러운지, 원본 이미지와 잘 어우러지는지 평가합니다.

Conclusion
본 논문에서는 Image-to-Image Translation을 위한 방법으로 조건부 적대적 네트워크를 사용하는 접근 방식을 제안하였습니다. 이 방법은 다양한 작업에서 높은 품질의 결과를 달성하여, 한 모델이 여러 다른 작업에 유효하게 사용될 수 있음을 입증하였습니다. 주목할만한 점은 판별자에서 L1 손실로 저주파 성분을 검출하고, PatchGANs으로 고주파 성분을 검출하여 학습을 가속화하고 생성 이미지의 품질을 향상시킨 것입니다.



